



爬虫下载腾讯视频周处除三害,第一次尝试,过程有点繁琐。
1.先进入腾讯视频的网站( https: //v.qq.com )
2. 找到相关视频并点击观看, 本文以周处除三害为例
2.1 进入网站后,鼠标右键点击检查,根据图片圈住部分进行操作
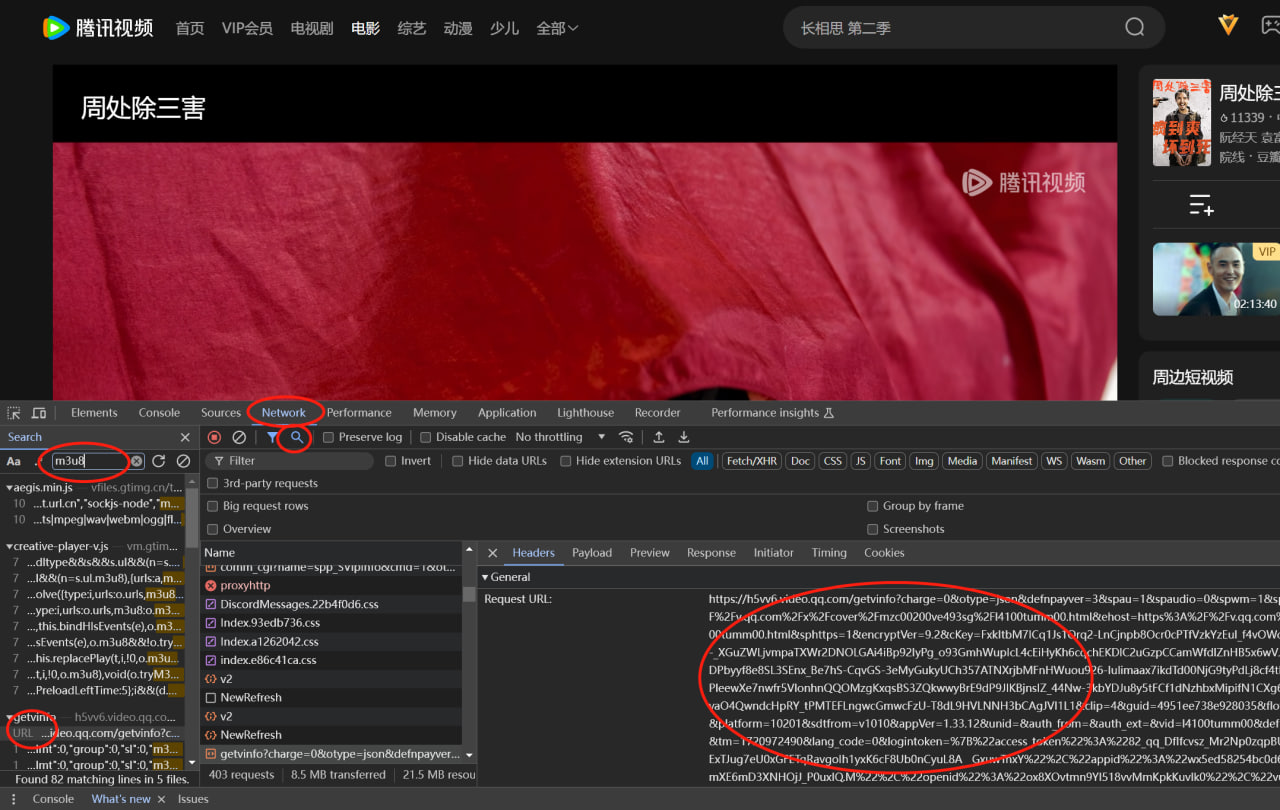
2.2 访问Request URL,就是图中最大的那一坨链接(ps: 复制完)
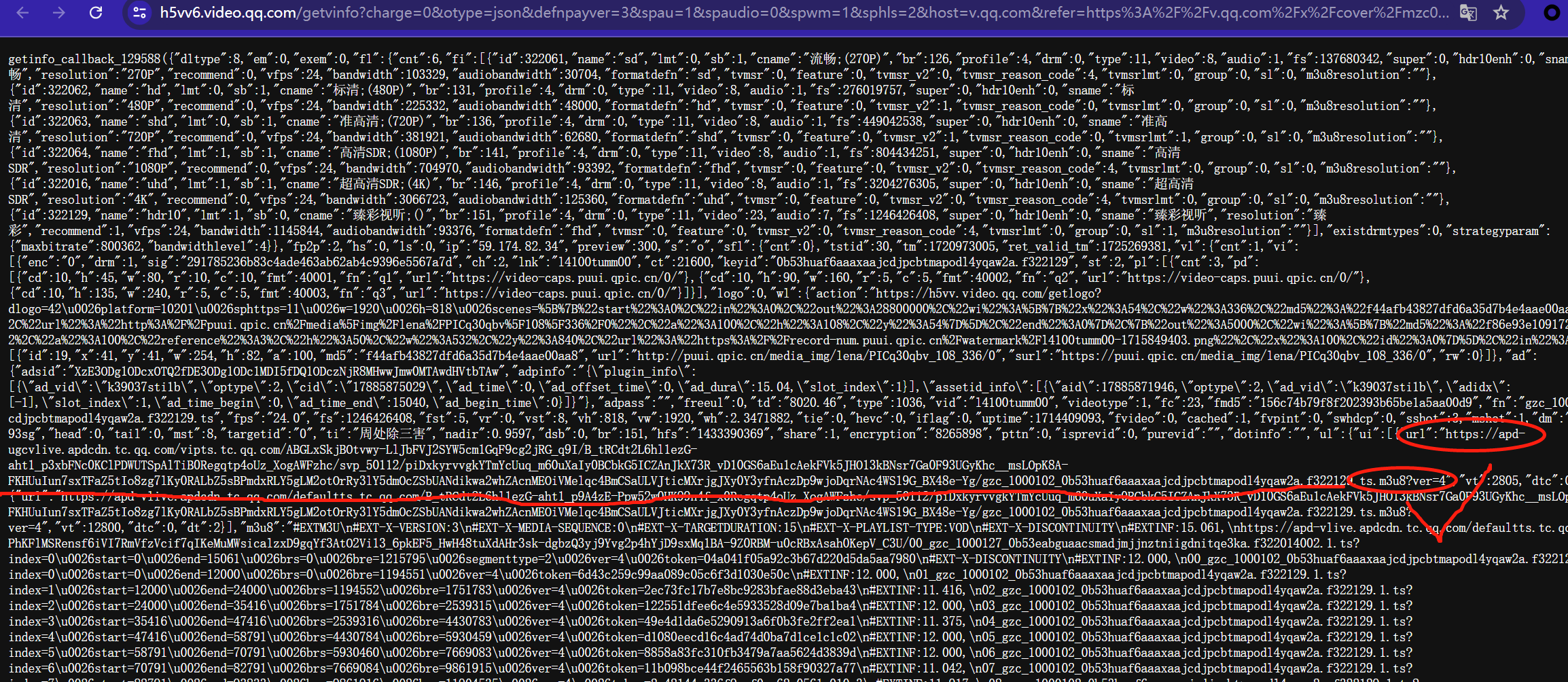
在访问链接后找到下图所示内容即是视频信息
3. 开始编码
import requests
import re
import json
from tqdm import tqdm
# 找出m3u8的url链接
url = 'https://apd-ugcvlive.apdcdn.tc.qq.com/vipts.tc.qq.com/ABGLxSkjBOtvwy-LlJbFVJ2SYW5cm1GqF9cg2jRG_q9I/B_tRCdt2L6hl1ezG-aht1_p3xbFNc0KClPDWUTSpAlTiB0Regqtp4oUz_XogAWFzhc/svp_50112/piDxkyrvvgkYTmYcUuq_m60uXaIy0BCbkG5ICZAnJkX73R_vD10GS6aEu1cAekFVk5JHO13kBNsr7Ga0F93UGyKhc__msLOpK8A-FKHUuIun7sxTFaZ5tIo8zg7lKy0RALbZ5sBPmdxRLY5gLM2otOrRy3lY5dmOcZSbUANdikwa2whZAcnMEOiVMelqc4BmCSaULVJticMXrjgJXy0Y3yfnAczDp9wjoDqrNAc4WS19G_BX48e-Yg/gzc_1000102_0b53huaf6aaaxaajcdjpcbtmapodl4yqaw2a.f322129.ts.m3u8?ver=4'
# 请求体,必要的UA认证
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.status_code)
# 获取m3u8响应内容
m3u8_response = response.content.decode('utf-8')
# 使用正则表达式提取每个视频片段的信息
pattern = re.compile(r'#EXTINF:(\d+\.\d+),\n(\S+)')
matches = pattern.findall(m3u8_response)
# 将提取的信息组织成JSON格式
video_segments = [{'duration': float(match[0]), 'url': match[1]} for match in matches]
result_json = {'video_segments': video_segments}
# 添加前缀, 根据不同视频的ts前缀添加, 这种前缀就是m3u8的url去掉最后一个'/'后gzc_1000102_0b53huaf6aaaxaajcdjpcbtmapodl4yqaw2a.f322129.ts.m3u8?ver=4
prefix = 'https://apd-ugcvlive.apdcdn.tc.qq.com/vipts.tc.qq.com/ABGLxSkjBOtvwy-LlJbFVJ2SYW5cm1GqF9cg2jRG_q9I/B_tRCdt2L6hl1ezG-aht1_p3xbFNc0KClPDWUTSpAlTiB0Regqtp4oUz_XogAWFzhc/svp_50112/piDxkyrvvgkYTmYcUuq_m60uXaIy0BCbkG5ICZAnJkX73R_vD10GS6aEu1cAekFVk5JHO13kBNsr7Ga0F93UGyKhc__msLOpK8A-FKHUuIun7sxTFaZ5tIo8zg7lKy0RALbZ5sBPmdxRLY5gLM2otOrRy3lY5dmOcZSbUANdikwa2whZAcnMEOiVMelqc4BmCSaULVJticMXrjgJXy0Y3yfnAczDp9wjoDqrNAc4WS19G_BX48e-Yg/'
# 遍历ts列表
for segment in tqdm(result_json['video_segments']):
# 拼接url
segment['url'] = prefix + segment['url']
# 发起请求,获取ts的视频内容
video_data = requests.get(url =segment['url']).content
# 写入文件
with open('./周处除三害.mp4', mode='ab') as f:
f.write(video_data)
4. 运行后的结果

5. 查看效果,画质还是不错的

评论区